A Reinforcement Learning Based Multiple Strategy Framework for Tracking a Moving Target
Published:
Pursuit-evasion is a classic research topic in mobile robotics and gaming theory. Deep reinforcement learning advances rapidly in recent years, and solves many decision-making problem like go, atari and robots control. However, learning an end-to-end strategy in a complex task can be prohibitive. We propose a hierachical framework which composes the neural network and classical tracking algorithms and outperforms either single method.
Formally speaking, the pursuit-evasion problem involves two agents chasing and running in a plane. Both agents have identical dynamics settings and can control the linear and angular velocities. The pursuer’s goal is to reach the evader within a certain radius, while the evader tries to avoid this. There are obstacles on the plane, anyone fails if it gets in collision. In this project, we only consider the pursuit process.
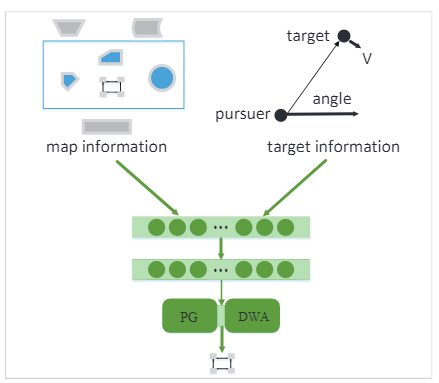
Above figure shows our hierarchical policy model. The top layer maps the environment and goal information to an high-level decision which determines which of the basic strategies to use, then the chosen strategy outputs the primitive action. The two basic strategies, dynamics window approach (DWA) and proportion guidance (PG) are specially picked.
DWA is a practical navigation method in mobile robots. It samples possible actions and evaluate each by the specified criterion, so that the robot can navigate to a static location without collision. But it cannot directly applies to track the moving target. PG is widely used in missile tracking, the only goal is to reach the moving target as fast as possible. However, it does not consider collisions. The following figures shows that use either along cannot achieve our goal, i.e. catching the moving target without collison.
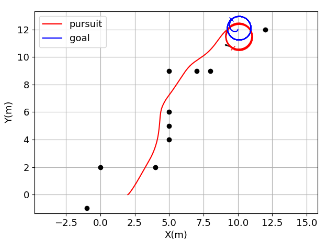 | 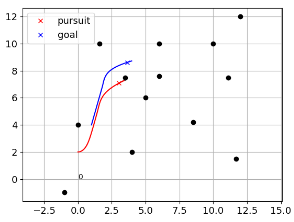 |
Using a neural network to change the tracking policy according to the condition is our solution. We adopts the proximal policy optimization algorithm to train the network. And the final performance is show