In my previous blog, I introduce the derivation of EM algorithm and convergence proof via defining its auxiliary function. Here I will introduce another method to prove the convergence of EM.
First let us denote X,Z as the observed variable and hidden variable, and denote D as collected iid samples, θ as the parameters.
PX,Z(D,z;θ)logPX(D;θ)=PZ∣X(z∣D;θ)PX(D;θ)=logPX,Z(D,z;θ)−logPZ∣X(z∣D;θ)
Taking expectations on both sides and using the fact that the left hand side does not depend on Z.
logPX(D;θ)=EZ∣X;θn(logPX,Z(D,z;θ))−EZ∣X;θn(logPZ∣X(z∣D;θ))=Q(θ,θn)+H(θ,θn)
where Q function is what EM algorithm actually optimize, and Q is the lower bound of log likelihood. Note that:
H(θ,θn)=−EZ∣X;θn(logPZ∣X(z∣D;θ))=−∫PZ∣X(z∣D;θn)logPZ∣X(z∣D;θ)dz=−∫pn(z)logp(z)dz=KL[pn∣∣p]+H[pn]
where KL[p∣∣q] is the Kullback-Leibler divergence between p and q, and H[p] the entropy of p itself. So H(θ,θn)≥0,logPX(D;θ)≥H(θ,θn)
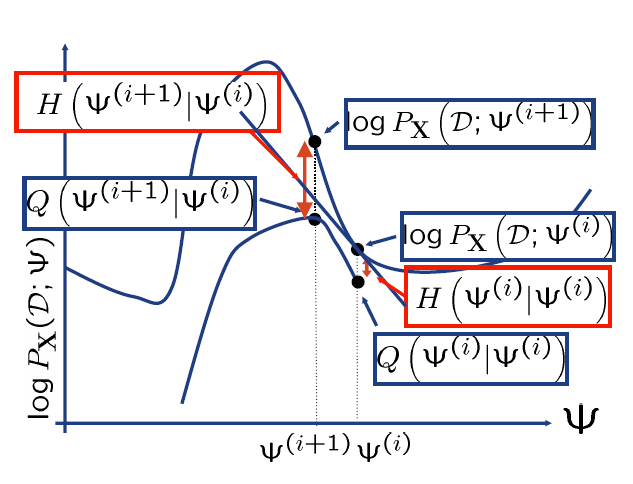
To prove the convergence of EM, we need to prove:
logPX(D;θn+1)≥logPX(D;θn)logPX(D;θn+1)−logPX(D;θn)=Q(θn+1,θn)+H(θn+1,θn)−Q(θn,θn)−H(θn,θn)=Q(θn+1,θn)−Q(θn,θn)+KL[pn∣∣pn+1]+H[pn]−KL[pn∣∣pn]−H[pn]=Q(θn+1,θn)−Q(θn,θn)+KL[pn∣∣pn+1]
In M step we optimize Q,Q(θn+1,θn)≥Q(θn,θn), so logPX(D;θn+1)−logPX(D;θn). The convergence of EM is proved, but note that there is no guarantee of convergence to global maximum.
And since in the proof, we just increase Q function rather than maximize it. So in M step any step that increases it is sufficient, it is very useful when M-step is itself non-trivial:
* e.g. if there is no closed-form solution one has to resort to numerical methods, like gradient ascent.
* can be computationally intensive, lots of iterations per M-step
* in these cases, it is usually better to just perform a few iterations and move on to the next E-step
* no point in precisely optimizing M-step if everything is going to change when we compute the new E-step
In previous part, I have derived the following form of Q function.
Q(θ,θn)=t=1∑Ti=0∑CP(Z=i∣X=xt;θn)logP(X=xt,Z=i;θ)
Next I will show how to derive it from the Q function above.
EZ∼P(z∣D;θn)(logPX,Z(D,z;θ))=EZ∼P(z∣D;θn)(t=1∑NlogPX,Z(xt,zt;θ))=t=1∑NEZ∼P(z∣D;θn)(logPX,Z(xt,zt;θ))=t=1∑NEZ∼P(zt∣xt;θn)(logPX,Z(xt,zt;θ))
