EM Algorithm Derivation and Auxiliary function
We often want to estimate model parameters from observed data, and the most common method is to maximize the maximum likelihood of a statistical model, i.e. maximum likelihood estimation (MLE). But in some cases the data is incomplete, e.g. some labels are missed or some variable cannot be observed, so directly applying MLE can be quite difficult. And Expectation–maximization (EM) algorithm is proposed to maximize the likelihood with these hidden variables.
The idea of the EM algorithm to solve hidden variables is to use a iterative method. We first guess the hidden data (Expectation step), then based on the observed data and guessed hidden data we can maximize the log-likelihood and solve our model parameters (Maximization step).
Next we will see the derivation of it with a simple example.
Suppose we weigh a batch of vehicles that leave the factory, and there two types of cars, which are labeled as 0 and 1. And we already know that the weight of each type conform the Gaussian distribution:
P(W=w∣Y=i)=G(w;μi,σi),i∈{0,1}
So if we have complete data, data={(w1,i1),(w2,i2),…,(wT,iT)}, we can simply maximize the log-likelihood with iid assumption:
logP(data)=t=1∑TlogP(W=wt,Y=it)=t=1∑T[logP(Y=it)+logP(W=wt∣Y=it)]
Adding the constrain ∑i=01P(Y=i)=1, and using Lagrange multiplier, we can solve it:
P(Y=i)μiσi2=T∑t=1TI(it,i)=∑t=1TI(it,i)∑t=1TI(it,i)wt=∑t=1TI(it,i)∑t=1TI(it,i)(wt−μi)2
I(x,y)=1, if x=y, otherwise 0.
But if all cars are covered with a black cloth, we cannot get the type. The data becomes {(w1),(w2),…,(wT)}. So the log-likelihood changes to:
logP(data)=t=1∑TlogP(W=wt)=t=1∑Tlogi=0∑1P(W=wt,Y=i)
Theoretically, we can compute gradient of this function and get maximum. However, you will find it quite difficult, since the sum is embedded in log. If we can extract the sum outside log, it can be much easier. Jensen’s inequality help to do this.
If f(x) is convex and X a random variable then:
E[f(X)]≥f(E[X])
The equal sign holds if and only if P(x=E[x])=1, i.e. X is a constant.
Here I just give an example to help intuitive understanding. Suppose X is discrete and P(X=x1)=t,P(X=x2)=1−t,f(x) is convex, we can get the following picture.

And if f(x) is concave, E[f(X)]≤f(E[X]).
Back to the log-likelihood. First we introduce a unknown distribution P~t(Y) with ∑i=01P~t(Y=i)=1,0≤P~t(Y=i)≤1. Given log is concave, apply Jensen's inequality:
logP(data)=t=1∑Tlogi=0∑1P~t(Y=i)P~t(Y=i)P(W=wt,Y=i)=t=1∑TlogE[P~(Y)P(W=wt,Y)]≥t=1∑TE[logP~(Y)P(W=wt,Y)]≥t=1∑Ti=0∑1P~t(Y=i)logP~t(Y=i)P(W=wt,Y=i)
Here we get a lower bound of the log-likelihood. Suppose we initialize all parameters μi,σi,P(i), if we can continuously increase this lower bound by iterating parameters, the log-likelihood also increases. EM actually uses two steps to increase the lower bound by iteration.
In E-step, through choosing P~t(Y=i), the lower bound increase to the log-likelihood. From Jensen's inequality, only when P~t(Y)P(W=wt,Y) is a constant, the lower bound equals the log-likelihood. So we can get the following result.
∵P~t(Y=i)P(W=wt,Y=i)=α,i={0,1}∴i=0∑1P(W=wt,Y=i)=αi=0∑1P~t(Y=i)=α∴P~t(Y=i)=∑i=01P(W=wt,Y=i)P(W=wt,Y=i)=P(Y=i∣W=wt)
So now we can represent the lower bound as:
Q(θ,θ~)=t=1∑Ti=0∑1P(Y=i∣W=wt;θ~)logP(Y=i∣W=wt;θ~)P(W=wt,Y=i;θ)
θ and θ~ both represent values of parameters μi,σi,P(Y=i). θ is fixed in this step. θ~ is what we want to change to increase Q(θ,θ~). Clearly if θ~=θ, the lower bound increase to the log-likelihood.
In E-step, we make the expected value of P(W=wt,Y=i;θ) as Q(θ,θ~) with θ~=θ. This is why it is called expectation step.
In M-step, we optimize Q(θ,θ~) by adjusting θ with θ~ fixed, and it is much easier to optimize than P(W=wt,Y=i;θ).
θ′=θargmaxQ(θ,θ~)=θargmaxt=1∑Ti=0∑1P(Y=i∣W=wt;θ~)logP(Y=i∣W=wt;θ~)P(W=wt,Y=i;θ)=θargmaxt=1∑Ti=0∑1P(Y=i∣W=wt;θ~)logP(W=wt,Y=i;θ)
Now we can make a summary:
Input: observed data {(w1),(w2),…,(wT)}, the form of conditional distribution P(Y=i∣W=wt;θ~), the form of joint distribution P(W=wt,Y=i;θ), and the maximum number of iteration steps N.
First initialize θ as θ0.
For n=1 to N
E-step: θ~=θn−1, compute P(Y=i∣W=wt;θn−1).
M-step:
θn=θargmaxQ(θ,θn−1)=θargmaxt=1∑Ti=0∑1P(Y=i∣W=wt;θn−1)logP(W=wt,Y=i;θ)
Though the example is simple, but we can generate it to any other model. Just replace W with all observed variable, and replace Y with all hidden variable.
In E-step, we fix model parameters, and optimize the conditional distribution of hidden data. And in M-step, what we do is to fix the distribution of hidden data and optimize the values of model parameters. This idea is called auxiliary functions in mathematics.
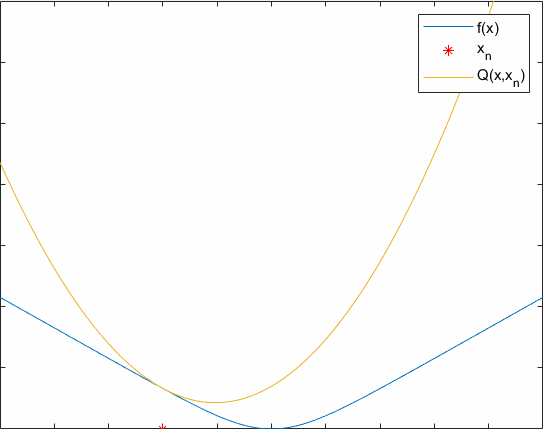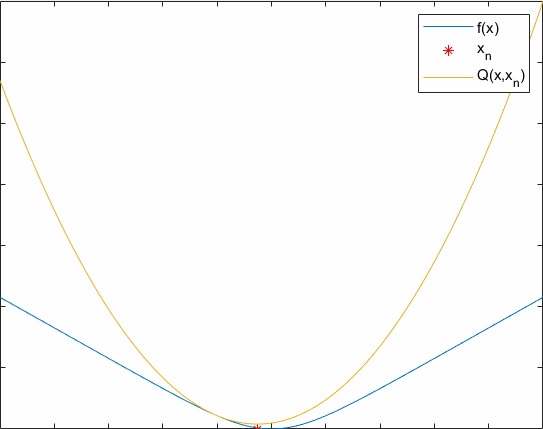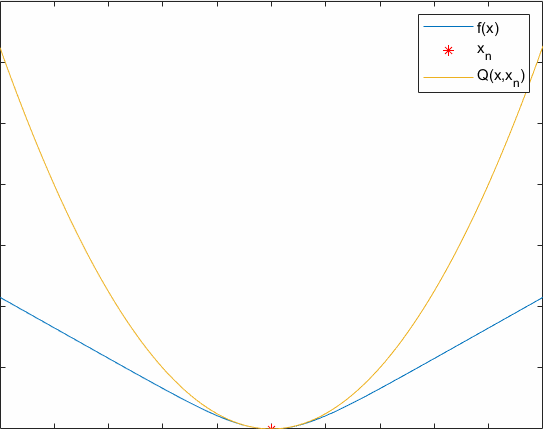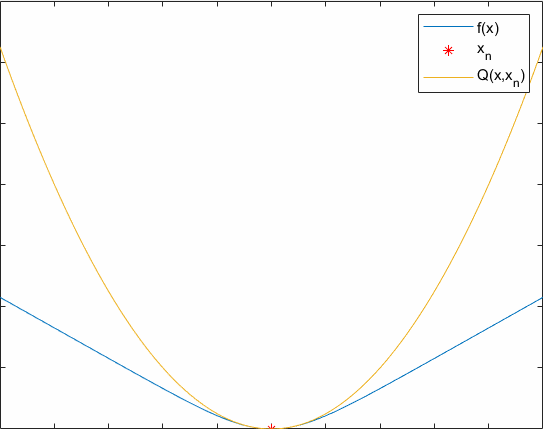
Q(x,y) is an auxiliary function for f(x), if it satisfies:
(i) Q(x,x)=f(x)
(ii) Q(x,y)≥f(x)
Recall the property of Q(θ,θ~), what we do is to construct an auxiliary function for −P(W=wt,Y=i;θ), since:
(i) −Q(θ,θ)=−P(W=wt,Y=i;θ)
(ii) −Q(θ,θ~)≥−P(W=wt,Y=i;θ)
The update rule of an auxiliary function is xn+1=argmaxxQ(x,xn).
A process of optimizing an auxiliary function is showed below. Hope it can help you understand the essence of EM.